AI-Driven Handbook Generator with Multi-Agent Orchestration (Pyragogy AI Village)
This n8n workflow is a modular, multi-agent AI orchestration system designed for the collaborative generation of Markdown-based handbooks. Inspired by peer learning and open publishing workflows, it simulates a content pipeline where specialized AI agents act in defined roles, enabling true AI–human co-creation and iterative refinement.
This project is a core component of Pyragogy, an open framework dedicated to ethical cognitive co-creation, peer AI–human learning, and human-in-the-loop automation for open knowledge systems. It implements the master orchestration architecture for the Pyragogy AI Village, managing a complex sequence of AI agents to process input, perform review, synthesis, and archiving, with a crucial human oversight step for final approval.
How It Works: A Deep Dive into the Workflow's Architecture
The workflow orchestrates a sophisticated content generation and review process, ideal for creating AI-driven knowledge bases or handbooks with human oversight.
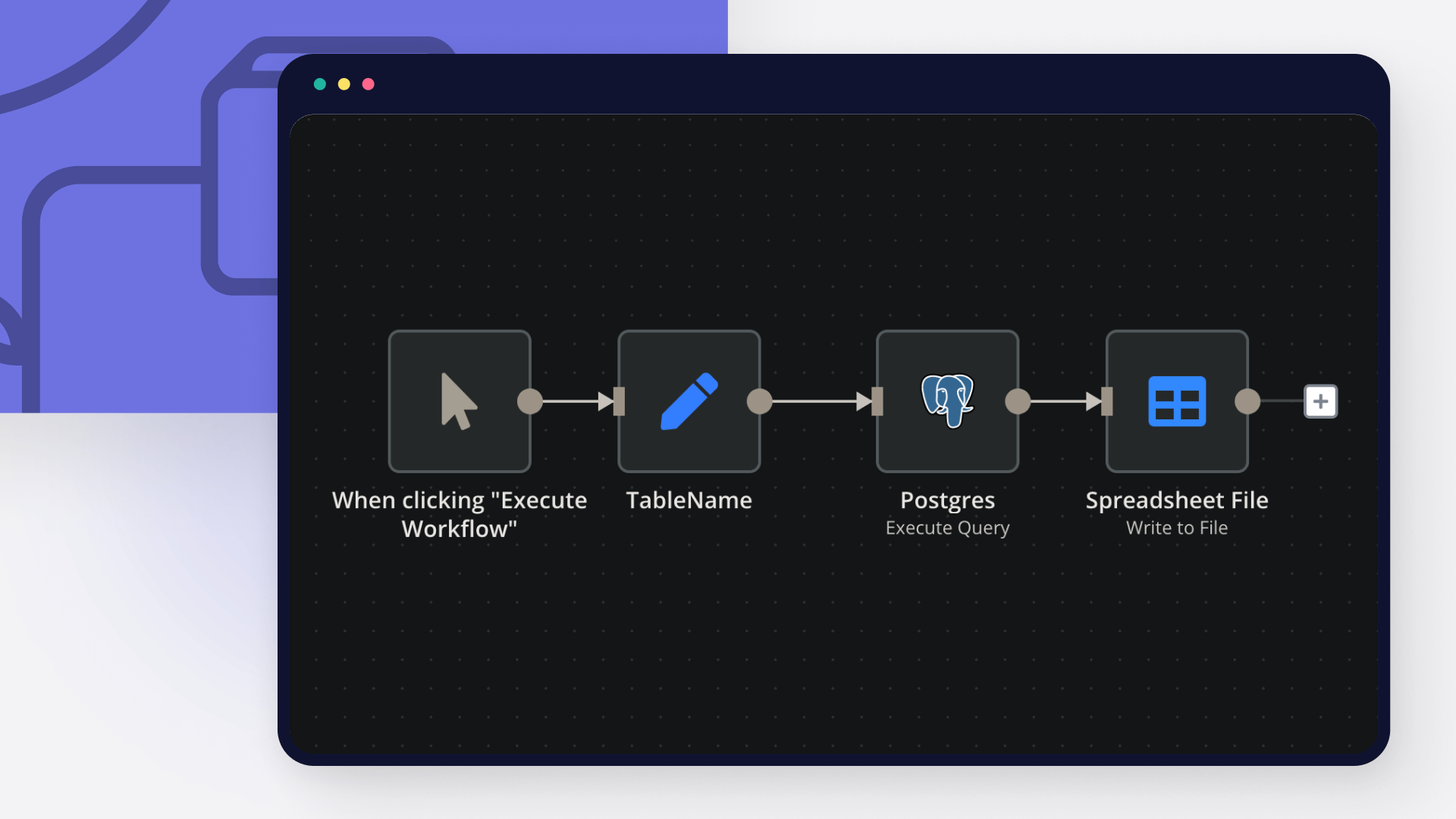
Webhook Trigger & Input:* The process begins when the workflow receives a JSON input via a Webhook* (specifically at /webhook/pyragogy/process). This input typically includes details like the handbook's title, initial text, and relevant tags.
Database Verification:* It first verifies the connection to a PostgreSQL database* to ensure data persistence.
Meta-Orchestrator:* A powerful Meta-Orchestrator* (powered by gpt-4o from OpenAI) analyzes the initial request. Its role is to dynamically determine and activate the optimal sequence of specialized AI agents required to fulfill the input, ensuring tasks are dynamically routed and assigned based on each agent’s responsibility.
Agent Execution & Iteration:** Each activated agent executes its step using OpenAI or custom endpoints. This involves:
Content Generation: Agents like the Summarizer and the Synthesizer generate new content or refine existing text.
Peer Review Board: A crucial aspect is the Peer Review Board, comprised of AI agents like the Peer Reviewer, the Sensemaking Agent, and the Prompt Engineer. This board evaluates the output for quality, coherence, and accuracy.
Reprocessing & Redrafting: If the review agents flag a major_issue, they trigger redrafting loops by generating specific feedback for the Synthesizer. This mechanism ensures iterative refinement until the content meets the required standards.
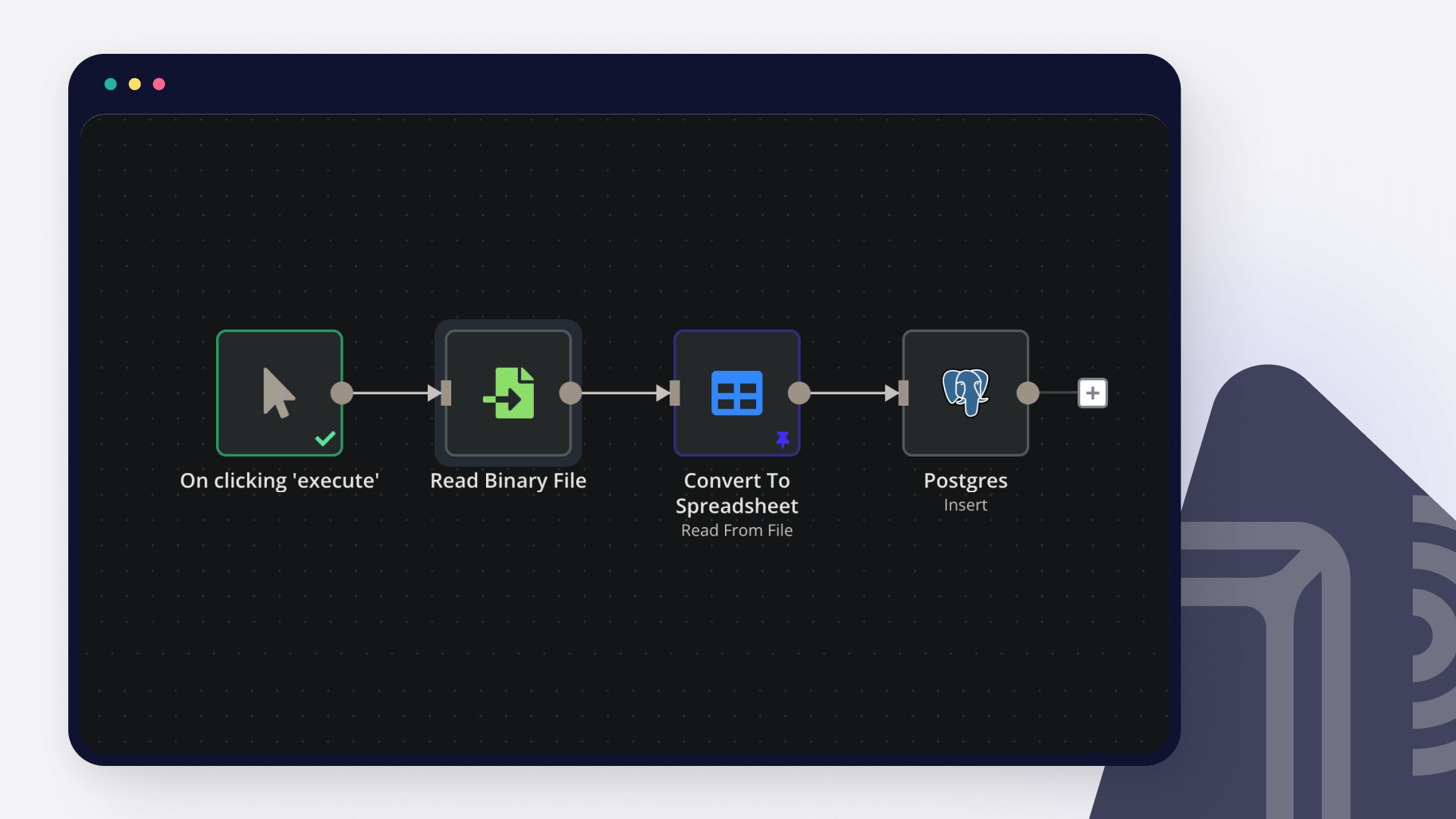
Human-in-the-Loop (HITL) Review:* For final approval, particularly for the Archivist agent's output, a human review process is initiated. An email is sent to a human reviewer, prompting them to approve, reject, or comment via a "Wait for Webhook" node. This ensures human oversight* and quality control.
Content Persistence & Versioning:** If the content is approved by the human reviewer:
It's saved to a PostgreSQL database (specifically to the handbook_entries and agent_contributions tables).
Optionally, the content can be committed to a GitHub repository for version control, provided the necessary environment variables are configured.
Notifications:* The final output and the sequence of executed agents can be sent as a notification to Slack*, if configured.
Observe the dynamic loop: orchestrate → assign → generate → review (AI/human) → store
Included AI Agents
This workflow leverages a suite of specialized AI agents, each with a distinct role in the content pipeline:
Meta-Orchestrator:** Determines the optimal sequence of agents to execute based on the input.
Summarizer Agent:** Summarizes text into key points (e.g., 3 key points).
Synthesizer Agent:** Synthesizes new text and effectively incorporates reprocessing feedback from review agents.
Peer Reviewer Agent:** Reviews generated text, highlighting strengths, weaknesses, and suggestions, and indicates major_issue flags.
Sensemaking Agent:** Analyzes input within existing context, identifying patterns, gaps, and areas for improvement.
Prompt Engineer Agent:** Refines or generates prompts for subsequent agents, optimizing their output.
Onboarding/Explainer Agent:** Provides explanations of the process or offers guidance to users.
Archivist Agent:** Prepares content for the handbook, manages the human review process, and handles archiving to the database and GitHub.
Setup Steps & Prerequisites
To get this powerful workflow up and running, follow these steps:
Import the Workflow: Import the pyragogy_master_workflow.json (or generate-collaborative-handbooks-with-gpt4o-multi-agent-orchestration-human-review.json) into your n8n instance.
Connect Credentials:
Postgres: Set up a Postgres Pyragogy DB credential (ID: pyragogy-postgres).
OpenAI: Configure an OpenAI Pyragogy credential (ID: pyragogy-openai) for all OpenAI agents. GPT-4o is highly suggested for optimal performance.
Email Send: Set up a configured email credential (e.g., for sending human review requests).
Define Environment Variables: Define essential environment variables (an .env.template is included in the repository). These include:
API base for OpenAI.
Database connection details.
(Optional) GitHub: For content persistence and versioning, configure GITHUB_ACCESS_TOKEN, GITHUB_REPOSITORY_OWNER, and GITHUB_REPOSITORY_NAME.
(Optional) Slack: For notifications, configure SLACK_WEBHOOK_URL.
Send a sample payload to your webhook URL (/webhook/pyragogy/process):
{
"title": "History of Peer Learning",
"text": "Peer learning is an educational approach where students learn from and with each other...",
"tags": ["education", "pedagogy"],
"requireHitl": true
}
Ideal For
This workflow is perfectly suited for:
Educators and researchers exploring AI-assisted publishing and co-authoring with AI.
Knowledge teams looking to automate content pipelines for internal or external documentation.
Anyone building collaborative Markdown-driven tools or AI-powered knowledge bases.
Documentation & Contributions: An Open Source and Collaborative Project
This workflow is an open-source project and community-driven. Its development is transparent and open to everyone.
We warmly invite you to:
Review it:** Contribute your analysis, identify potential improvements, or report issues.
Remix it:** Adapt it to your specific needs, integrate new features, or modify it for a different use case.
Improve it:** Propose and implement changes that enhance its efficiency, robustness, or capabilities.
Share it back:** Return your contributions to the community, either through pull requests or by sharing your implementations.
Every contribution is welcome and valued! All relevant information for verification, improvement, and collaboration can be found in the official repository:
🔗 GitHub – pyragogy-handbook-n8n-workflow