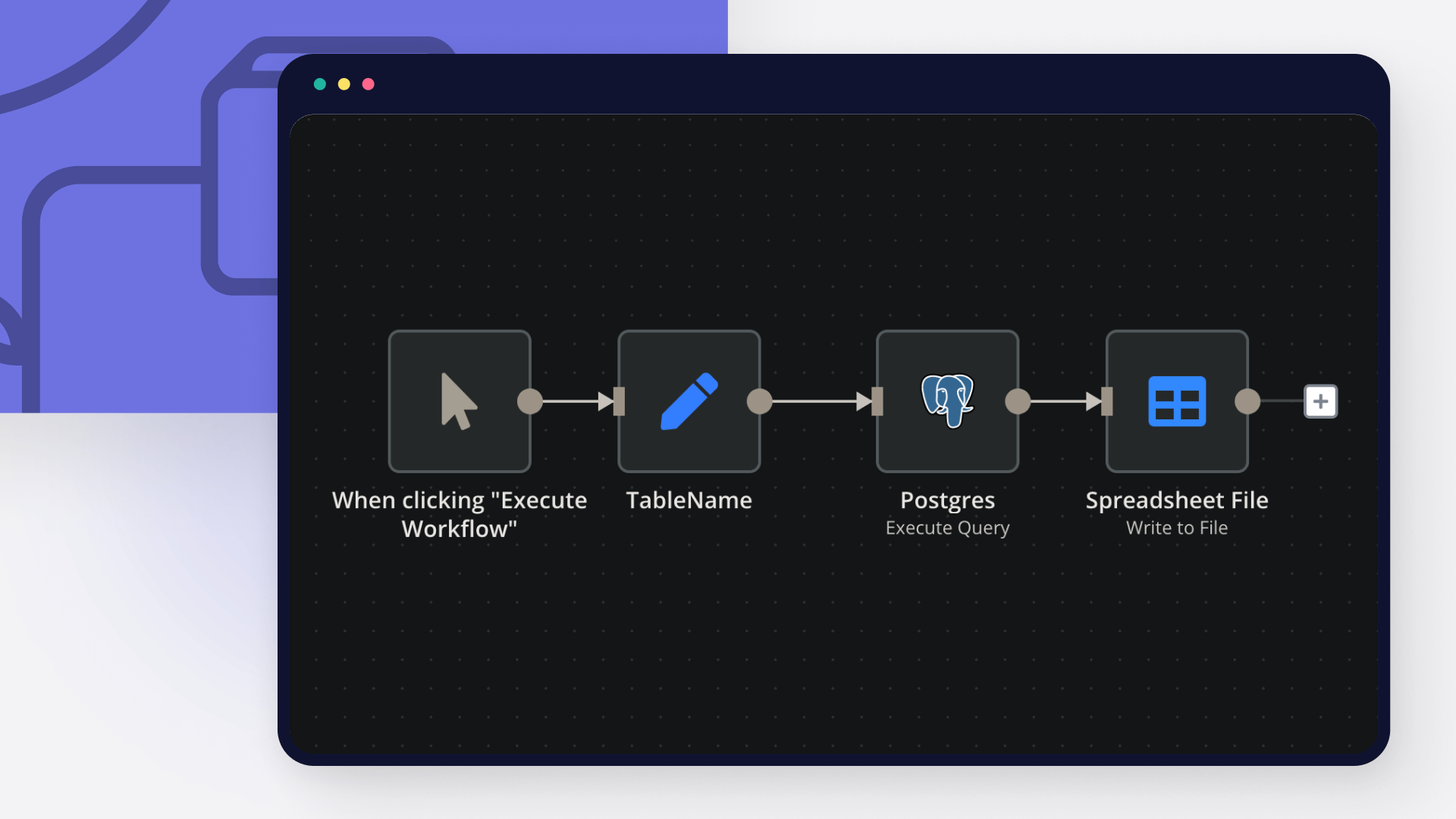
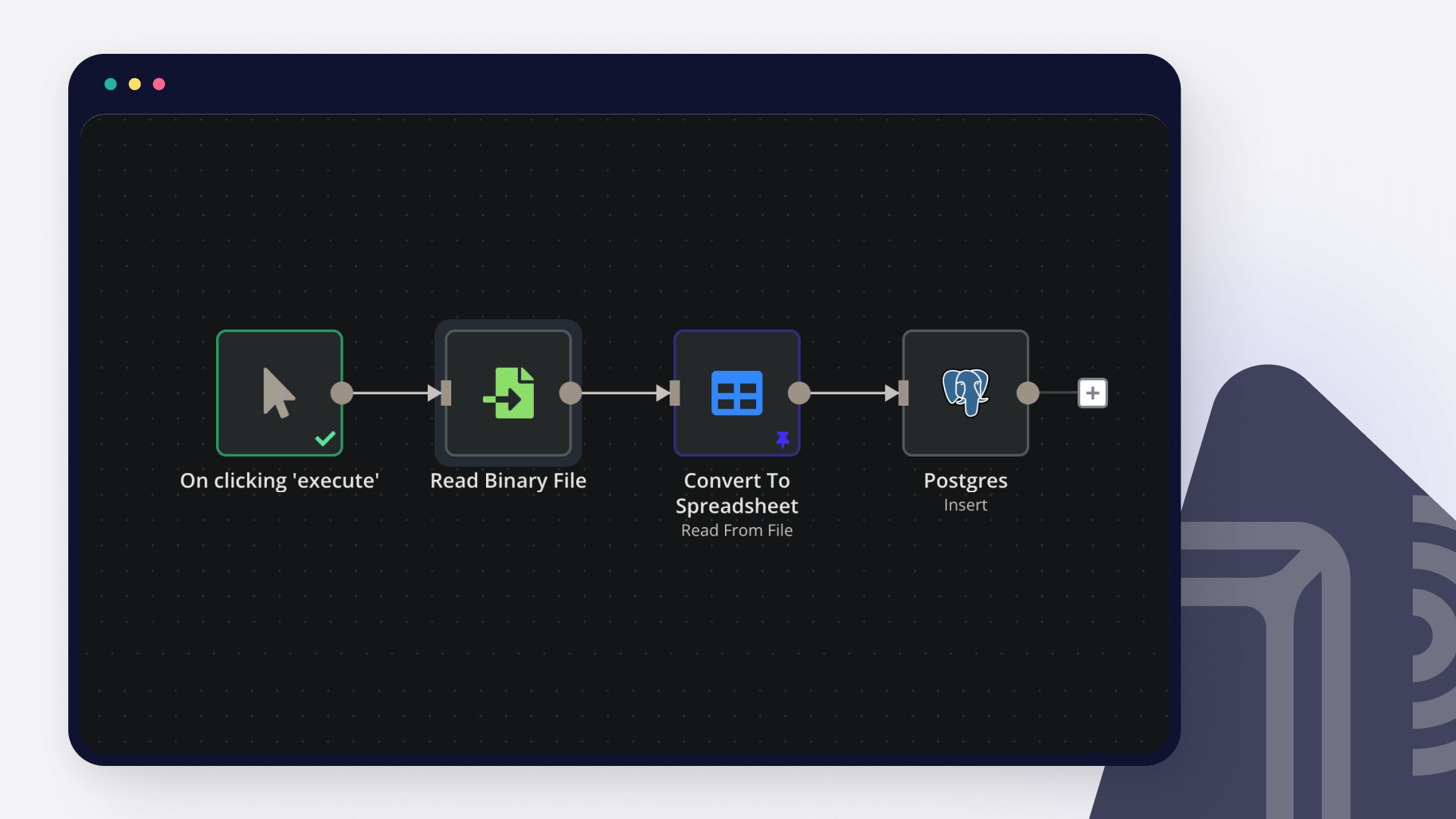
Interactive Knowledge Base Chat with Supabase RAG using AI 📚💬
Google Drive File Ingestion to Supabase for Knowledge Base 📂💾
Overview 🌟
This n8n workflow automates the process of ingesting files from Google Drive into a Supabase database, preparing them for a knowledge base system. It supports text-based files (PDF, DOCX, TXT, etc.) and tabular data (XLSX, CSV, Google Sheets), extracting content, generating embeddings, and storing data in structured tables. This is a foundational workflow for building a company knowledge base that can be queried via a chat interface (e.g., using a RAG workflow). 🚀
Problem Solved 🎯
Manually managing a knowledge base with files from Google Drive is time-consuming and error-prone. This workflow solves that by:
Automatically ingesting files from Google Drive as they are created or updated.
Extracting content** from various file types (text and tabular).
Generating embeddings for text-based files to enable vector search.
Storing data in Supabase for efficient retrieval.
Handling duplicates and errors to ensure data consistency.
Target Audience:
Knowledge Managers**: Build a centralized knowledge base from company files.
Data Teams**: Automate the ingestion of spreadsheets and documents.
Developers**: Integrate with other workflows (e.g., RAG for querying the knowledge base).
Workflow Description 🔍
This workflow listens for new or updated files in Google Drive, processes them based on their type, and stores the extracted data in Supabase tables for later retrieval. Here’s how it works:
File Detection: Triggers when a file is created or updated in Google Drive.
File Processing: Loops through each file, extracts metadata, and validates the file type.
Duplicate Check: Ensures the file hasn’t been processed before.
Content Extraction:
Text-based Files: Downloads the file, extracts text, splits it into chunks, generates embeddings, and stores the chunks in Supabase.
Tabular Files: Extracts data from spreadsheets and stores it as rows in Supabase.
Metadata Storage: Stores file metadata and basic info in Supabase tables.
Error Handling: Logs errors for unsupported formats or duplicates.
Nodes Breakdown 🛠️
Detect New File 🔔
Type**: Google Drive Trigger
Purpose**: Triggers the workflow when a new file is created in Google Drive.
Configuration**:
Credential: Google Drive OAuth2
Event: File Created
Customization**:
Specify a folder to monitor specific directories.
Detect Updated File 🔔
Type**: Google Drive Trigger
Purpose**: Triggers the workflow when a file is updated in Google Drive.
Configuration**:
Credential: Google Drive OAuth2
Event: File Updated
Customization**:
Currently disconnected; reconnect if updates need to be processed.
Process Each File 🔄
Type**: Loop Over Items
Purpose**: Processes each file individually from the Google Drive trigger.
Configuration**:
Input: {{ $json.files }}
Customization**:
Adjust the batch size if processing multiple files at once.
Extract File Metadata 🆔
Type**: Set
Purpose**: Extracts metadata like file_id, file_name, mime_type, and web_view_link.
Configuration**:
Fields:
file_id: {{ $json.id }}
file_name: {{ $json.name }}
mime_type: {{ $json.mimeType }}
web_view_link: {{ $json.webViewLink }}
Customization**:
Add more metadata fields if needed (e.g., size, createdTime).
Check File Type ✅
Type**: IF
Purpose**: Validates the file type by checking the MIME type.
Configuration**:
Condition: mime_type contains supported types (e.g., application/pdf, application/vnd.openxmlformats-officedocument.spreadsheetml.sheet).
Customization**:
Add more supported MIME types as needed.
Find Duplicates 🔍
Type**: Supabase
Purpose**: Checks if the file has already been processed by querying knowledge_base.
Configuration**:
Operation: Select
Table: knowledge_base
Filter: file_id = {{ $node['Extract File Metadata'].json.file_id }}
Customization**:
Add additional duplicate checks (e.g., by file name).
Handle Duplicates 🔄
Type**: IF
Purpose**: Routes the workflow based on whether a duplicate is found.
Configuration**:
Condition: {{ $node['Find Duplicates'].json.length > 0 }}
Customization**:
Add notifications for duplicates if desired.
Remove Old Text Data 🗑️
Type**: Supabase
Purpose**: Deletes old text data from documents if the file is a duplicate.
Configuration**:
Operation: Delete
Table: documents
Filter: metadata->>'file_id' = {{ $node['Extract File Metadata'].json.file_id }}
Customization**:
Add logging before deletion.
Remove Old Data 🗑️
Type**: Supabase
Purpose**: Deletes old tabular data from document_rows if the file is a duplicate.
Configuration**:
Operation: Delete
Table: document_rows
Filter: dataset_id = {{ $node['Extract File Metadata'].json.file_id }}
Customization**:
Add logging before deletion.
Route by File Type 🔀
Type**: Switch
Purpose**: Routes the workflow based on the file’s MIME type (text-based or tabular).
Configuration**:
Rules: Based on mime_type (e.g., application/pdf for text, application/vnd.openxmlformats-officedocument.spreadsheetml.sheet for tabular).
Customization**:
Add more routes for additional file types.
Download File Content 📥
Type**: Google Drive
Purpose**: Downloads the file content for text-based files.
Configuration**:
Credential: Google Drive OAuth2
File ID: {{ $node['Extract File Metadata'].json.file_id }}
Customization**:
Add error handling for download failures.
Extract PDF Text 📜
Type**: Extract from File (PDF)
Purpose**: Extracts text from PDF files.
Configuration**:
File Content: {{ $node['Download File Content'].binary.data }}
Customization**:
Adjust extraction settings for better accuracy.
Extract DOCX Text 📜
Type**: Extract from File (DOCX)
Purpose**: Extracts text from DOCX files.
Configuration**:
File Content: {{ $node['Download File Content'].binary.data }}
Customization**:
Add support for other text formats (e.g., TXT, RTF).
Extract XLSX Data 📊
Type**: Extract from File (XLSX)
Purpose**: Extracts tabular data from XLSX files.
Configuration**:
File ID: {{ $node['Extract File Metadata'].json.file_id }}
Customization**:
Add support for CSV or Google Sheets.
Split Text into Chunks ✂️
Type**: Text Splitter
Purpose**: Splits extracted text into manageable chunks for embedding.
Configuration**:
Chunk Size: 1000
Chunk Overlap: 200
Customization**:
Adjust chunk size and overlap based on document length.
Generate Text Embeddings 🌐
Type**: OpenAI
Purpose**: Generates embeddings for text chunks using OpenAI.
Configuration**:
Credential: OpenAI API key
Operation: Embedding
Model: text-embedding-ada-002
Customization**:
Switch to a different embedding model if needed.
Store Text in Supabase 💾
Type**: Supabase Vector Store
Purpose**: Stores text chunks and embeddings in the documents table.
Configuration**:
Credential: Supabase credentials
Operation: Insert Documents
Table Name: documents
Customization**:
Add metadata fields to store additional context.
Store Tabular Data 💾
Type**: Supabase
Purpose**: Stores tabular data in the document_rows table.
Configuration**:
Operation: Insert
Table: document_rows
Columns: dataset_id, row_data
Customization**:
Add validation for tabular data structure.
Store File Metadata 📋
Type**: Supabase
Purpose**: Stores file metadata in the document_metadata table.
Configuration**:
Operation: Insert
Table: document_metadata
Columns: file_id, file_name, file_type, file_url
Customization**:
Add more metadata fields as needed.
Record in Knowledge Base 📚
Type**: Supabase
Purpose**: Stores basic file info in the knowledge_base table.
Configuration**:
Operation: Insert
Table: knowledge_base
Columns: file_id, file_name, file_type, file_url, upload_date
Customization**:
Add indexes for faster lookups.
Log File Errors ⚠️
Type**: Supabase
Purpose**: Logs errors for unsupported file types.
Configuration**:
Operation: Insert
Table: error_log
Columns: error_type, error_message
Customization**:
Add notifications for errors.
Log Duplicate Errors ⚠️
Type**: Supabase
Purpose**: Logs errors for duplicate files.
Configuration**:
Operation: Insert
Table: error_log
Columns: error_type, error_message
Customization**:
Add notifications for duplicates.
Interactive Knowledge Base Chat with Supabase RAG using GPT-4o-mini 📚💬
Introduction 🌟
This n8n workflow creates an interactive chat interface that allows users to query a company knowledge base using Retrieval-Augmented Generation (RAG). It retrieves relevant information from text documents and tabular data stored in Supabase, then generates natural language responses using OpenAI’s GPT-4o-mini model. Designed for teams managing internal knowledge, this workflow enables users to ask questions like “What’s the remote work policy?” or “Show me the latest budget data” and receive accurate, context-aware responses in a conversational format. 🚀
Problem Statement 🎯
Managing a company knowledge base can be a daunting task—employees often struggle to find specific information buried in documents or spreadsheets, leading to wasted time and inefficiencies. Traditional search methods may not understand natural language queries or provide contextually relevant results. This workflow solves these issues by:
Offering a chat-based interface for natural language queries, making it easy for users to ask questions in their own words.
Leveraging RAG to retrieve relevant text and tabular data from Supabase, ensuring responses are accurate and context-aware.
Supporting diverse file types, including text-based files (e.g., PDFs, DOCX) and tabular data (e.g., XLSX, CSV), for comprehensive knowledge access.
Maintaining conversation history to provide context during interactions, improving the user experience.
Target Audience 👥
This workflow is ideal for:
HR Teams**: Quickly access company policies, employee handbooks, or benefits documents.
Finance Teams**: Retrieve budget data, expense reports, or financial summaries from spreadsheets.
Knowledge Managers**: Build a centralized assistant for internal documentation, streamlining information access.
Developers**: Extend the workflow with additional tools or integrations for custom use cases.
Workflow Description 🔍
This workflow consists of a chat interface powered by n8n’s Chat Trigger node, an AI Agent node for RAG, and several tools to retrieve data from Supabase. Here’s how it works step-by-step:
User Initiates a Chat: The user interacts with a chat interface, sending queries like “Summarize our remote work policy” or “Show budget data for Q1 2025.”
Query Processing with RAG: The AI Agent processes the query using RAG, retrieving relevant data from Supabase tables and generating a response with OpenAI’s GPT-4o-mini model.
Data Retrieval and Response Generation: The workflow uses multiple tools to fetch data:
Retrieves text chunks from the documents table using vector search.
Fetches tabular data from the document_rows table based on file IDs.
Extracts full document text or lists available files as needed.
Generates a natural language response combining the retrieved data.
Conversation History Management: Stores the conversation history in Supabase to maintain context for follow-up questions.
Response Delivery: Formats and sends the response back to the chat interface for the user to view.
Nodes Breakdown 🛠️
Start Chat Interface 💬
Type**: Chat Trigger
Purpose**: Provides the interactive chat interface for users to input queries and receive responses.
Configuration**:
Chat Title: Company Knowledge Base Assistant
Chat Subtitle: Ask me anything about company documents!
Welcome Message: Hello! I’m your Company Knowledge Base Assistant. How can I help you today?
Suggestions: What is the company policy on remote work?, Show me the latest budget data., List all policy documents.
Output Chat Session ID: true
Output User Message: true
Customization**:
Update the title and welcome message to align with your company branding (e.g., HR Knowledge Assistant).
Add more suggestions relevant to your use case (e.g., What are the company benefits?).
Process Query with RAG 🧠
Type**: AI Agent
Purpose**: Orchestrates the RAG process by retrieving relevant data using tools and generating responses with OpenAI’s GPT-4o-mini.
Configuration**:
Credential: OpenAI API key
Model: gpt-4o-mini
System Prompt: You are a helpful assistant for a company knowledge base. Use the provided tools to retrieve relevant information from documents and tabular data. If the query involves tabular data, format it clearly in your response. If no relevant data is found, respond with "I couldn’t find any relevant information. Can you provide more details?"
Input Field: {{ $node['Start Chat Interface'].json.message }}
Customization**:
Switch to a different model (e.g., gpt-3.5-turbo) to adjust cost or performance.
Modify the system prompt to change the tone (e.g., more formal for HR use cases).
Retrieve Text Chunks 📄
Type**: Supabase Vector Store (Tool)
Purpose**: Retrieves relevant text chunks from the documents table using vector search.
Configuration**:
Credential: Supabase credentials
Operation Mode: Retrieve Documents (As Tool for AI Agent)
Table Name: documents
Embedding Field: embedding
Content Field: content_text
Metadata Field: metadata
Embedding Model: OpenAI text-embedding-ada-002
Top K: 10
Customization**:
Adjust Top K to retrieve more or fewer results (e.g., 5 for faster responses).
Ensure the match_documents function (see prerequisites) is defined in Supabase.
Fetch Tabular Data 📊
Type**: Supabase (Tool, Execute Query)
Purpose**: Retrieves tabular data from the document_rows table based on a file ID.
Configuration**:
Credential: Supabase credentials
Operation: Execute Query
Query: SELECT row_data FROM document_rows WHERE dataset_id = $1 LIMIT 10
Tool Description: Run a SQL query - use this to query from the document_rows table once you know the file ID you are querying. dataset_id is the file_id and you are always using the row_data for filtering, which is a jsonb field that has all the keys from the file schema given in the document_metadata table.
Customization**:
Modify the query to filter specific columns or add conditions (e.g., WHERE dataset_id = $1 AND row_data->>'year' = '2025').
Increase the LIMIT for larger datasets.
Extract Full Document Text 📜
Type**: Supabase (Tool, Execute Query)
Purpose**: Fetches the full text of a document by concatenating all text chunks for a given file_id.
Configuration**:
Credential: Supabase credentials
Operation: Execute Query
Query: SELECT string_agg(content_text, ' ') as document_text FROM documents WHERE metadata->>'file_id' = $1 GROUP BY metadata->>'file_id'
Tool Description: Given file id fetch the text from the documents
Customization**:
Add filters to the query if needed (e.g., limit to specific metadata fields).
List Available Files 📋
Type**: Supabase (Tool, Select)
Purpose**: Lists all files in the knowledge base from the document_metadata table.
Configuration**:
Credential: Supabase credentials
Operation: Select
Schema: public
Table: document_metadata
Tool Description: Use this tool to fetch all documents including the table schema if the file is csv, excel or xlsx
Customization**:
Add filters to list specific file types (e.g., WHERE file_type = 'application/pdf').
Modify the columns selected to include additional metadata (e.g., file_size).
Manage Chat History 💾
Type**: Postgres Chat Memory (Tool)
Purpose**: Stores and retrieves conversation history to maintain context.
Configuration**:
Credential: Supabase credentials (Postgres-compatible)
Table Name: n8n_chat_history
Session ID Field: session_id
Session ID Value: {{ $node['Start Chat Interface'].json.sessionId }}
Message Field: message
Sender Field: sender
Timestamp Field: timestamp
Context Window Length: 5
Customization**:
Increase the context window length for longer conversations (e.g., 10 messages).
Add indexes on session_id and timestamp in Supabase for better performance.
Format and Send Response 📤
Type**: Set
Purpose**: Formats the AI Agent’s response and sends it back to the chat interface.
Configuration**:
Fields:
response: {{ $node['Process Query with RAG'].json.output }}
Customization**:
Add additional formatting to the response if needed (e.g., prepend with a timestamp or apply markdown formatting).
Setup Instructions 🛠️
Prerequisites 📋
n8n Setup:
Ensure you’re using n8n version 1.0 or higher.
Enable the AI features in n8n settings.
Supabase:
Create a Supabase project and set up the following tables:
documents: id (uuid), content_text (text), embedding (vector(1536)), metadata (jsonb)
document_rows: id (uuid), dataset_id (varchar), row_data (jsonb)
document_metadata: file_id (varchar), file_name (varchar), file_type (varchar), file_url (text)
knowledge_base: id (serial), file_id (varchar), file_name (varchar), file_type (varchar), file_url (text), upload_date (timestamp)
n8n_chat_history: id (serial), session_id (varchar), message (text), sender (varchar), timestamp (timestamp)
Add the match_documents function to Supabase to enable vector search:
CREATE OR REPLACE FUNCTION match_documents (
query_embedding vector(1536),
match_count int DEFAULT 5,
filter jsonb DEFAULT '{}'
) RETURNS TABLE (
id uuid,
content_text text,
metadata jsonb,
similarity float
) LANGUAGE plpgsql AS $$
BEGIN
RETURN QUERY
SELECT
documents.id,
documents.content_text,
documents.metadata,
1 - (documents.embedding <=> query_embedding) as similarity
FROM documents
WHERE documents.metadata @> filter
ORDER BY similarity DESC
LIMIT match_count;
END;
$$;